Real-Time Data Streaming and Search Indexing with Azure - Part 4 - CDC event processing

In the last part we looked at the CDC setup and the event structure that Debezium utilizes to stream changes from our Azure SQL Server to the Azure Event Hub. This post will go through the CDC event-processing necessary to consume the events and push them into our targets queues for the Azure AI Search index to consume.
This post should include some fun coding, so lets jump in.
Event processing
My preferred approach in Azure is to use Azure Functions to consume events from Azure Event Hub, as they provide a simple and scalable way to process streaming data. Alternatively, you could use Container App Jobs or other compute services, depending on your requirements and deployment preferences.
Event routing
As the Azure Event Hub can publish Events that affect any configured CDC table in the database we first need to enable us to identify what has been changed, and where should the change be routed. As I am a big fan of configuration (see my configuration series) this is a prime target to utilize some configuration to make my change feed processor as much configurable as possible.
To support this I've come up with this configuration.
Insert Event
{
"ChangeFeedTargets": [
{
"Source": {
"Database": "sqldbproductsdev",
"Schema": "dbo",
"TableName": "Products"
},
"Destination": {
"RouteDatacontract": "Products",
"AzureQueueName": "products-feed"
},
"Triggers": [
"Insert",
"Update",
"Delete"
]
}
]
}
Here we have options to provide multiple targets, with a source and destination. and what triggers we would like to listen to.
if we investigate the configuration in detail we see that the example will consume events from the dbo.Products table and changes of Insert/Update/Delete will be published to a Azure Storage Queue named products-feed. We can also see that we specify a RouteDatacontract with value Products. This setting will be used to determine which data contract we will use to parse the event data and publish to products-feed.
Event listener
For the Event listener we have an Event Hub input binding to our azure function. We will consume Azure Event hub events and use our event routing configuration to determine where we should send the messages to.
- Consume the
eventDatainto aChangeFeedParser. - Log information about the event.
- Gather configured routes.
- Use our
RouteMessageFactoryimplementation to get a defined data contract. - Queue the change to the be consumed by downstream component.
Change Processor
[Function(nameof(CDCDataChangePipeline))]
public async Task CDCDataChangePipeline(
[EventHubTrigger("evh-product-dev", Connection = "eventhubnamespace_connectionstring", IsBatched = false)] byte[] eventData)
{
if (eventData.Length == 0)
return;
var parser = new ChangeFeedParser(JObject.Parse(Encoding.UTF8.GetString(eventData)));
if (parser.GetChangeFeedType() == ChangeType.Table)
{
var database = parser.DatabaseInfo.Database;
var schema = parser.TableInfo.Schema;
var table = parser.TableInfo.Table;
var operation = parser.Operation;
var changedAt = parser.TableInfo.ChangedAt.ToString("O");
_logger.LogInformation("Event from Change Feed received:");
_logger.LogInformation("- Database: {Database}", database);
_logger.LogInformation("- Object: {Schema}.{Table}", schema, table);
_logger.LogInformation("- Operation: {Operation}", operation);
_logger.LogInformation("- Captured At: {ChangedAt}", changedAt);
var routes = _settings.ChangeFeedTargets
.Where(setting => setting.Source.Database == database
&& setting.Source.Schema == schema
&& setting.Source.TableName == table
&& setting.Triggers.Contains(operation.ToString()))
.ToList();
if (routes.Count != 0)
{
_logger.LogInformation("Routing event...");
foreach (var route in routes)
{
_logger.LogInformation("- Routing to Queue: {Queue}", route.Destination.AzureQueueName);
Fields fields;
if (parser.Operation == Operation.Insert || parser.Operation == Operation.Update)
fields = parser.After;
else
fields = parser.Before;
var routeMessage = RoutableMessageFactory.Create(route.Destination.RouteDatacontract, operation, fields);
var message = JsonConvert.SerializeObject(routeMessage);
var queueClient = _queueServiceClient.GetQueueClient(route.Destination.AzureQueueName);
await queueClient.SendMessageAsync(message);
}
}
else
{
_logger.LogInformation("- No Configured Routes: Ignoring event");
}
}
await Task.Yield();
}
}
On a closer look we see the code that hooks into the configuration we got setup earlier. If none of the configuration matches our scenario ignore the event.
For systems that require old database events later in the timeframe, i would build in a event store that persist the all events, even ignored. The event playback can be useful for newly created sub-systems that need to backfill data.
Routes
var routes = _settings.ChangeFeedTargets
.Where(setting => setting.Source.Database == database
&& setting.Source.Schema == schema
&& setting.Source.TableName == table
&& setting.Triggers.Contains(operation.ToString()))
.ToList();
if (routes.Count != 0)
{
//..
}
else
{
_logger.LogInformation("- No Configured Routes: Ignoring event");
}
Sending the message is trivial as we just create the queueClient with the target route and sends the message.
Target processing
In the same function app (in my example, this can be a totally separate function or other reading queue mechanism, such as container app jobs) we listen to the products-feed and pushes a update to the search index.
Products Feed
public class ProductsFeed
{
private readonly ILogger<ProductsFeed> _logger;
private readonly SearchClient _searchClient;
public ProductsFeed(ILogger<ProductsFeed> logger, SearchClient searchClient)
{
_logger = logger;
_searchClient = searchClient;
}
[Function(nameof(ProductsFeed))]
public async Task Run([QueueTrigger("products-feed")] string message)
{
var routeMessage = JsonConvert.DeserializeObject<RouteMessage<Product>>(message);
if (routeMessage == null)
{
throw new InvalidOperationException("Failed to deserialize message");
}
if (routeMessage.Operation == Parser.Operation.Delete)
{
await _searchClient.DeleteDocumentsAsync(nameof(ProductSearchIndexItem.ProductId), [routeMessage.Data.ProductId.ToString()]);
return;
}
var indexItem = new ProductSearchIndexItem
{
ProductId = routeMessage.Data.ProductId.ToString(),
Name = routeMessage.Data.Name,
Description = routeMessage.Data.Description
};
await _searchClient.MergeOrUploadDocumentsAsync([indexItem]);
}
}
Reviews Feed
public class ReviewsFeed
{
private readonly ILogger<ReviewsFeed> _logger;
private readonly SearchClient _searchClient;
public ReviewsFeed(ILogger<ReviewsFeed> logger, SearchClient searchClient, QueueServiceClient queueServiceClient)
{
_logger = logger;
_searchClient = searchClient;
}
[Function(nameof(ReviewsFeed))]
public async Task Run([QueueTrigger("reviews-feed")] string message)
{
var routeMessage = JsonConvert.DeserializeObject<RouteMessage<Review>>(message)
?? throw new InvalidOperationException("Failed to deserialize message");
var documentResponse = await _searchClient.GetDocumentAsync<ProductSearchIndexItem>(routeMessage.Data.ProductId.ToString());
var document = documentResponse?.Value
?? throw new InvalidOperationException($"Document with ID {routeMessage.Data.ProductId} not found");
if (routeMessage.Operation is Parser.Operation.Delete or Parser.Operation.Update)
{
var review = document.Reviews.FirstOrDefault(r => r.ReviewId == routeMessage.Data.ReviewID);
if (review != null)
{
document.Reviews.Remove(review);
if (routeMessage.Operation == Parser.Operation.Delete)
{
await _searchClient.MergeOrUploadDocumentsAsync([document]);
return;
}
}
else if (routeMessage.Operation == Parser.Operation.Delete)
{
return;
}
}
if (routeMessage.Operation != Parser.Operation.Delete)
{
document.Reviews.Add(new ReviewIndexItem
{
ReviewId = routeMessage.Data.ReviewID,
Rating = routeMessage.Data.Rating,
Comment = routeMessage.Data.Comment
});
}
await _searchClient.MergeOrUploadDocumentsAsync([document]);
}
}
For the reviews-feed we are leveraging Database operations to judge if we should add, update or remove a review from the search document.
With this setup, the flow works as follows:
- Database Change: A change (insert, update, or delete) occurs in the source database table.
- CDC & Debezium: The change is captured by CDC and streamed via Debezium to Azure Event Hub.
- Event Routing: An Azure Function listens to the Event Hub, processes the event, and routes it to the appropriate Azure Storage Queue based on configuration.
- Queue Processing: Another Azure Function (like
ProductsFeed) listens to the queue, deserializes the message, and updates the Azure AI Search index accordingly.
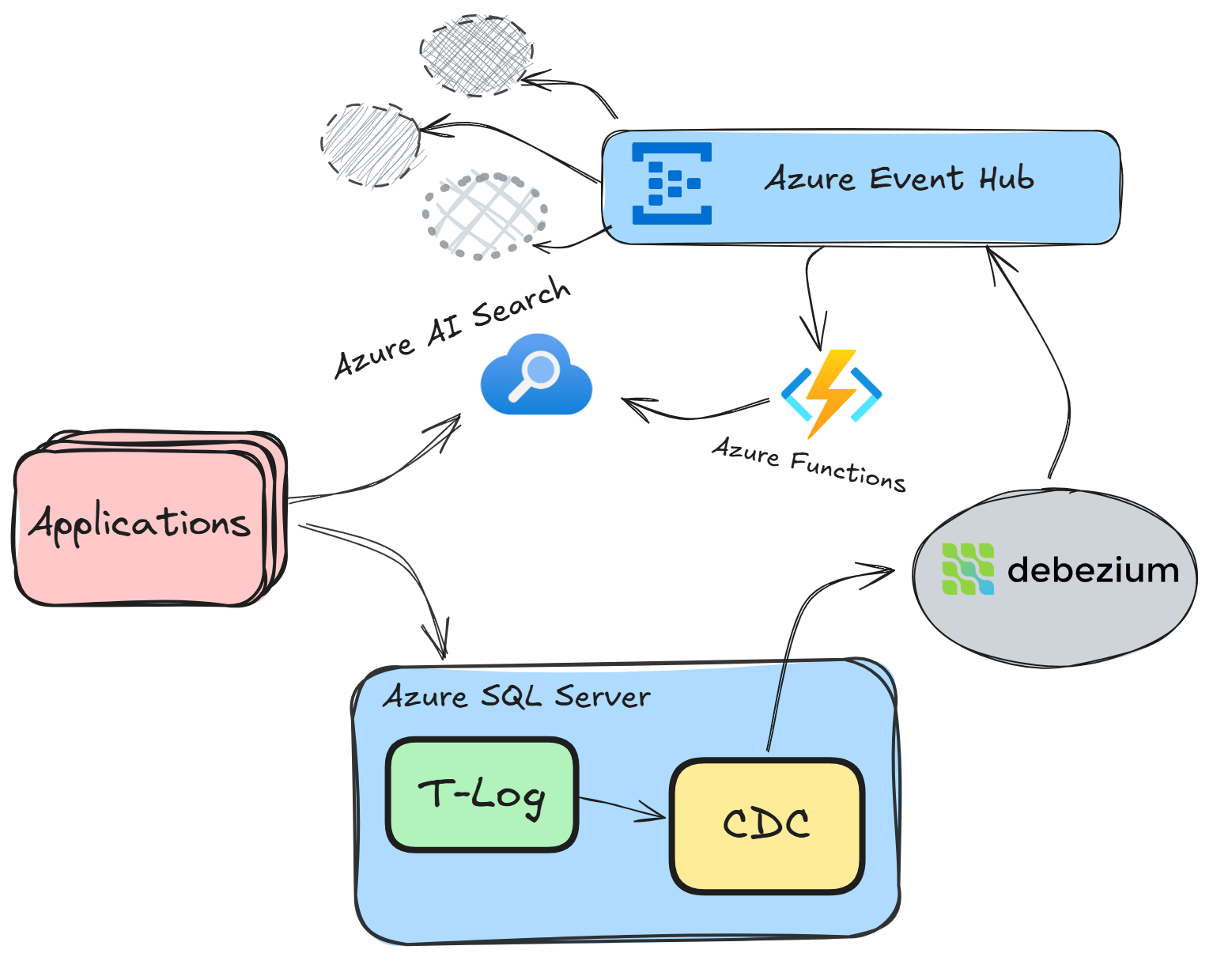
This architecture ensures that changes in your database are reflected in your search index in near-real time, with each component decoupled for scalability and resilience.
Monitoring & Operations
Azure Functions with a QueueTrigger automatically retry message processing up to 5 times by default. If the function continues to fail (for example, due to deserialization errors or downstream service issues), the message is moved to a poison queue named <queue-name>-poison (products-feed-poison). This ensures that failed messages are not lost and can be inspected or reprocessed later. You do not need to implement custom retry or dead-letter logic. Just let the exceptions bubble up.
For production environments, monitoring is essential. Application Insights provides tracking of function executions, while Azure Monitor helps track queue lengths and processing times—critical indicators of system health.
Consider setting up alerts on poison queues to catch processing failures early. A simple alert when products-feed-poison has any messages can prevent significant headaches. During initial deployment, closely monitor logs to identify any recurring issues and adjust function scaling to match your throughput requirements.
For multi-cloud environments, OpenTelemetry offers a vendor-neutral observability framework that integrates well with Azure Functions through the OpenTelemetry SDK, allowing collection and export of telemetry data to your preferred visualization tools.
Wrapping Up
In this part, we built the core event processing pipeline: consuming CDC events, routing them to the correct queues, and updating the Azure AI Search index in near-real time. With Azure Functions built-in retry and poison queue support, the system is resilient to transient failures. just remember to monitor the poison queues for any messages that couldn't be processed after several attempts.
This completes the main data flow from database changes to search index updates. In the next post in this series, I'll will look into Azure AI Search and its capabilities. That post will be somewhat decoupled from the code we've seen so far, as I want to demonstrate and experiment with Azure AI Search features at a level that would be impractical to implement directly into our data pipeline (as it would introduce too much implementation overhead).
As always you can find all the code for this sample project at github
Thanks for following along—happy coding!